列式存储之PREWHERE优化
最近学习到了列式存储引擎中的 PREWHERE 优化,写下此文来记录一下与此有关的所见所想。
列式存储数据库的查询流程
以这么一条 SQL 语句为例
1 | SELECT b, c, e FROM t WHERE a > 1 AND c = 3; |
对于一个简单的列式存储数据库,它的查询流程可能是这样的:
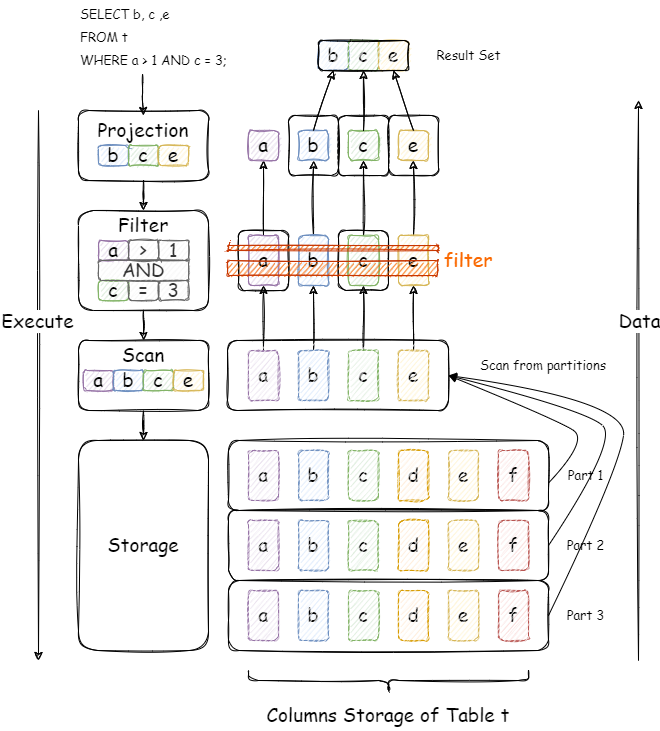
首先会构建一个如图这样的 Projection-Filter-Scan 执行计划,其中 Scan 算子会从底层存储引擎中读取数据。在一般的列式存储引擎中,列数据会被存储在多个 Partition 中,存储引擎可以以 Parition 会单位读取列数据,并依次向上层算子返回数据。
再上图的所示的例子中,所有需要进行计算的列 (a, b, c, e) 都会被读取到内存中,并且经由 Filter 算子计算进行行筛选,最后再由 Projection 算法进行最终的列筛选。
这样的执行过程,其实有一部分开销可以省去的。比如对于列 b 和 列 e,它们并不会参与 Filter 的计算,我们是否可以提前进行筛选,避免不必要的 b 和 e 的读取以及拷贝呢?这便是 PREWHERE 优化的思想。
PREWHERE 优化
PREWHERE 优化的思想其实很简单,就是将 WHERE 中的条件下推到 Scan 算子中,并尽可能移除 Filter 算子。具体来说,Scan 算子在进行最小读取单位 (可以是 Block,也可以是 Partition 等等,看引擎具体的实现) 的读取时,先预读取 PREWHERE 条件中的列进行预筛选。如果这些行中包含的所有数据都不满足筛选条件,那么这个 Block 或 Partition 就可以直接跳过,不用再读剩下的列了。在这种情况下,会大大节省读取带宽,提升读取速度。
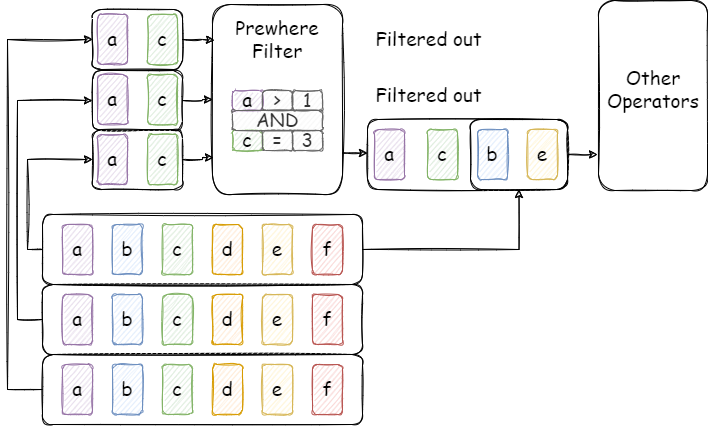
当然,PREWHERE 不是万金油,当条件语句中的列覆盖了所有需要读取的列是,经过了 PREWHERE 优化的查询就和原始的所有数据一起过 Filter 的查询相差无几了,甚至可能会更慢 (更多分支、内存拷贝等因素)。因此,在实际的实现中,往往会有一些启发式的规则,结合上相关列的数量、在内存中的大小等因素,选择性地将 WHERE 中的条件转移到 PREWHERE 并下推到 Scan。
ClickHouse 中的 PREWHERE
ClickHouse[1] (以下简称 CK)很早就实现了 PREWHERE[2],并将其作为了一个可以手动使用的语句,例如:
1 | SELECT * FROM t PREWHERE a > 1; |
不过,CK 并不倡导用户手动使用 PREWHERE 语句,而是让 CK 的 SQL 引擎自行优化。CK 会在构建查询执行器 (InterpreterQuery) 时对 AST 进行一次分析,按照一定规则 (可自行查阅源码。规则虽然不少,但源码较为简单,可以比较容易地看懂) 来选择哪些以及多少条件语句会从 WHERE 中移至 PREWHERE 中,并改写 AST,最后再生成最终的执行器。
Databend 中的 PREWHERE 实现
近日,我在 Databend 中进行了 PREWHERE 的初步实现[3],也是对 Databend 的源码有了更多的了解。
我的实现主要是分为两部分,第一部分是如何将 PREWHERE 的相关信息下推到 Scan 算子,更具体的,是如何下推到支持 PREWHERE 优化的 Fuse Engine 中。第二部分就是 Fuse Engine 如何进行前文所述的 PREWHERE 数据读取。
PREWHERE 下推
与 CK 不同,Databend 的 SQL 层更加模块化。在我这次的实现中,我决定基于 Rule-Based Optimizer(RBO) 来进行 PREWHERE 信息下推。
对于 Filter-LogicalGet 这样一个 Pattern,我们可以将 Filter 中的条件语句全部打包成一个 PrewhereInfo 塞给 LogicalGet,然后在一路推给下层引擎。
可以看出,目前这一部分还是很 naive 的,首先是条件语句几乎是全部传给下一层,除了涉及到所有要读取的列的语句;其次,目前并没有根据统计信息做一些启发式的规则,这个还需要后续的优化。
另外,让优化器模块来负责 PREWHERE 信息的生成可能不太好,以后修改起来可能会比较麻烦,比如现在还没支持的一个点: Projection 剪枝,就需要牵扯到 prune_columns 这个 Rule。还需要找到一个更好的方法来实现,可以参考其他列式存储数据库的实现方法 (如 DuckDB, Doris 等)。
数据读取
Fuse Engine 数据读取相关的源码设计的很巧妙。它将数据读取的流程设计为了一个状态机,这样可以把整个读取流程划分为多个状态。这样做的好处是,可以将同步与异步逻辑分开,提升运行的效率。另外一个好处就是,代码写起来逻辑会更加清晰,代码的维护与修改也更加简单。
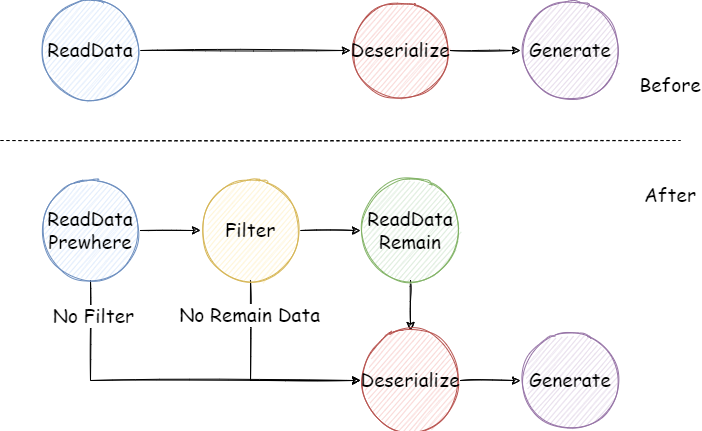
如图所示,我将以前的 ReadData 拆分为了 ReadPrewhere 与 ReadRemain 两个状态,分别用来读取 PREWHERE 所需要的列与补全剩余列。初次之外,还增加了一个 Filter 状态用来对 ReadDataPrewhere 之后的数据进行过滤,并生成一个 Boolean 类型的列来表示每一行的过滤结果,用 FilterColumn 来表示。值得注意的是,如果没有 Filter,即没有 PREWHERE 信息,则可退化为最初的状态机;另外如果所有列都在 PREWHERE 中,那么在 Filter 之后便可以直接转到 Deserialize 进行 DataBlock 的生成(其实并不会出现这种情况,因为如上文所说,如果所有列都在条件语句中,则不会进行 PREWHERE 优化)。
另外一个小细节是,FilterColumn 与 ReadDataPrewhere 后的 raw data 需要从 Filter 一直传递到 Deserialize,以便合并与过滤 (这里是否会有不少内存拷贝的开销?C++可以只传指针,rustc 和 LLVM 的优化应该也会保证性能吧。但比起 IO 上的开销,内存拷贝的开销应该可以说是微乎其微了)。
当然,在具体的代码实现中还有很多小细节,这里就不做赘述了。
性能对比
测试机器相关信息:
- OS: Ubuntu 18.04 LTS (Bionic Beaver)
- Disk: 885G / 1.9T (50%)
- CPU: Intel Xeon Gold 5218R @ 80x 2.924GHz [46.0°C]
- RAM: 8993MiB / 95152MiB
这里进行了一个简单的性能对比。使用的数据集是 https://github.com/datafuselabs/databend/blob/main/tests/logictest/suites/ydb/select1-1.test 这里面的插入数据。我将这些数据每五个作为一次插入,并重复插入直至 21828 条数据。这里是为了保证有一定的数据量,并且数据能够打散在不同的 Partition 中。这里使用的 SQL 语句为:
1 | select * from t1 where a < 174 and b < 130; |
其中 174 和 130 分别是 a 列和 b 列相对平均的值。我使用了 hyperfine 工具来做简单的 benchmark 测试,预热运行 3 次,正式运行 10 次。测试结果如下:
PREWHER 优化之前:
| Mean [ms] | Min [ms] | Max [ms] |
|---|---|---|
| 856.5 ± 18.5 | 837.5 | 892.0 |
PREWHERE 优化之后:
| Mean [ms] | Min [ms] | Max [ms] |
|---|---|---|
| 847.0 ± 12.5 | 829.0 | 872.3 |
可以看到,PREWHERE 优化之后此查询语句的运行速度大概提升了 10ms (1.11%),并不是特别明显。并且其他语句诸如 select * from t1 where a < 174 and b > 130; 并未见到明显提升,甚至 PREWHERE 之后的结果更逊一筹。这里差别不明显的原因主要有以下几点:
- Databend 在
PREWHERE优化之前,便会将Filter整体下推到 Fuse Engine,用于Parition的剪枝,也就是会根据 min-max 等索引信息预先过滤掉一些Partition。所以对于一些数据或查询语句,PREWHERE优化之前的性能已经很好了。 - 对于一些查询语句,
Parition无法预先被过滤掉。如果一个Partition内数据量较大,且不满足PREWHERE条件,那么PREWHERE优化的提升效果会很明显。后续优化数据读取逻辑之后(并非每次读一个Partition,而是更加细化),可能会见到比较明显的差别。
本次性能测试还是比较 naive 的。首先是直接使用的 Debug 产物进行测试,其次是数据集太小,且数据分布不太符合真实场景,之后可以考虑使用 TPC-H 进行测试。
接下来可以继续做的
- 如上文所说,
PREWHERE优化还可以对下推到 Fuse Engine 的Projection(不是 SQL 的Projection,是 Fuse Engine 需要返回给上层的数据列) 进行剪枝。 PREWHERE列的选取还可以结合统计数据进行启发式优化。- 目前 Fuse Engine 读取数据的最小单元是
Partition,如果Partition数量少并且一个Partition中的数据量很大的话 (一次性 Insert 大量数据、后期Partition的 Compaction 会导致这种结果),PREWHERE的优化意义便会变得很小 (甚至负优化?)。数据块的读取这方面也亟待优化。
REFERENCE
- [1] https://github.com/ClickHouse/ClickHouse
- [2] https://clickhouse.com/docs/en/sql-reference/statements/select/prewhere
- [3] https://github.com/datafuselabs/databend/pull/7340
致谢
- 感谢 @sundy-li 大佬不厌其烦地答疑解惑与指导。
- 感谢 @leiysky 大佬在群里对我多次关于 SQL 层相关源码问题的解答。
- 感谢 @b41sh 与 @xudong.w 两位大佬的 Code Review。
- 感谢 @ClSlaid 大佬的 Approval。
- 感谢 ClickHouse 的源码。
- 感谢实验室强大的服务器。
- 感谢 VSCode 与 Rust Analyzer。
CHANGELOG
- 2022-09-16 Prewhere 优化修改为将 filter predicates 全部下推。https://github.com/datafuselabs/databend/pull/7646
- 2022-09-11 修复 read rows 统计信息错误。https://github.com/datafuselabs/databend/pull/7566
- 2022-09-09 优化列数据读取流程,减少反序列化次数。https://github.com/datafuselabs/databend/pull/7551
- 2022-08-31 初版实现。https://github.com/datafuselabs/databend/pull/7340