TiDB Flashback 之 MVCC Query 的实现思路 有幸和 @disking 与 @JmPotato 两位哥哥一同参加了今年(2021)TiDB 社区举办的 Hackthon。我们的项目简单来说就是基于 TiDB 的 MVCC 的特性实现一些新的功能。项目的 RFC 文档:https://github.com/Long-Live-the-DoDo/rfc 。
在本项目我负责第一个功能点:MVCC Query in SQL。简单来说就是为 TiDB 的数据表增加两个虚拟列 _tidb_mvcc_ts 与 _tidb_mvcc_op。众所周知,TiDB 中每一个数据表中的数据都是以 Key-Value 的形式存放在 TiKV 中,Key 是一条行记录的标识,它带有 MVCC 版本信息(ts);而 Value 就是这一条行记录的具体内容,它多列的数据拼接而成。TiDB 在读取数据时只会读取当前事务下能看到的最新数据,而我要做的就是能让它看到所有版本的数据。
一言以蔽之,我要实现的便是当 SQL 语句中存在 _tidb_mvcc_ts 或 _tidb_mvcc_op 两列时,会查询到所有的历史版本(以及它们的 MVCC 时间戳与操作类型)。
准备工作 除了 TiDB 与 TiKV 的开发环境准备之外,需要做的一个准备工作就是了解 TiDB 和 TiKV 的代码结构与它们的数据流,也就是要去大致了解它们的源码,而这也是最耗时间的一个过程,所以我的代码量并不大,但是却花了很长时间才写完。
于是我根据我需要改动的部分,结合 PingCAP 的官方博客,对源码进行了一波学习:
Select 流程:
如何将查询下推到 TiKV 并执行:
Insert 流程:
一条 SQL 语句的具体执行流程:
TiKV MVCC 读写流程:
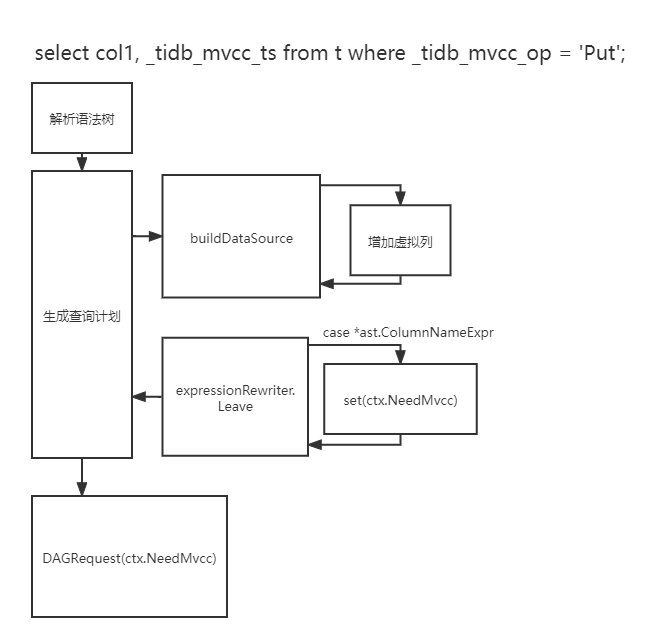
MVCC 信息查询功能 TiDB 侧实现 TiDB 负责 SQL 语句的解析与查询计划的构建。所以 TiDB 侧的修改主要分为两个部分:第一个是查询计划构建引入虚拟列,第二个是提示 TiKV 需要读取所有版本的数据。下图是 TiDB 中需要修改的部分:
查询计划构建引入虚拟列 以
1 select _tidb_mvcc_ts from t;
为例,当 PlanBuilder 读取到 t 时,它会调用 buildDataSource 为查询计划构造逻辑上的数据源(也就是要查询的表),如果这里不做任何处理,当 TiDB 执行前进行各种元信息(比如查询的列是否存在等)时就会认为 _tidb_mvcc_ts 不是表 t 的列,从而执行失败,所以我们只需要在 buildDataSource 的时候加入虚拟列即可,让 TiDB 认为这个表就是有 _tidb_mvcc_ts 和 _tidb_mvcc_op 这两列的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 func (b *PlanBuilder) error ) { mvccTsCol := ds.newExtraMVCCTsSchemaCol() ds.Columns = append (ds.Columns, model.NewExtraMVCCTsColInfo()) schema.Append(mvccTsCol) names = append (names, &types.FieldName{ DBName: dbName, TblName: tableInfo.Name, ColName: model.ExtraMVCCTsName, OrigColName: model.ExtraMVCCTsName, }) ds.TblCols = append (ds.TblCols, mvccTsCol) mvccOpCol := ds.newExtraMVCCOpSchemaCol() ds.Columns = append (ds.Columns, model.NewExtraMVCCOpColInfo()) schema.Append(mvccOpCol) names = append (names, &types.FieldName{ DBName: dbName, TblName: tableInfo.Name, ColName: model.ExtraMVCCOpName, OrigColName: model.ExtraMVCCOpName, }) ds.TblCols = append (ds.TblCols, mvccOpCol) }
其中与 MVCC 有关的数据结构与函数都是本次新加入的。
NeedMvcc 标志 我在查询计划构建的过程中引入了 NeedMvcc 标志来标记本次查询是否需要 MVCC 信息。具体来说,是在遍历语法树生成查询计划时,如果遇到了 _tidb_mvcc_ts 或 _tidb_mvcc_op,则将这个标识即为 true。这里的实现比较简单粗暴,直接将 NeedMvcc 存到了 SessionCtx 中,也就是存到了整个 Session 的上下文中(所以用完之后需要清理为 false)。我觉得更优雅的方式是存放到 LogicPlan 与 PhysicPlan 中,然后层层传递到 Executor,但为了简单快捷的实现,我就直接放到了会话上下文中。
设置 NeedMvcc 具体发生在 exoressionRewriter 这个 Visitor 执行 Leave 时,如果它需要接受的原本的语法树节点是 ast.ColumnNameExpr 类型,也就是列名时,我们可以检查这个列名是否是 _tidb_mvcc_ts 或 _tidb_mvcc_op,如果是,则将 NeedMvcc 设置为 true,否则不变:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 func (er *expressionRewriter) bool ) { case v := inNode.(type ) { case *ast.ColumnNameExpr: if v.Name.Name.L == model.ExtraMVCCOpName.L || v.Name.Name.L == model.ExtraMVCCTsName.L { er.sctx.GetSessionVars().NeedMvcc = true } } }
接下来就是在通过物理计划构造 Executor 并构造对 TiKV 的 RPC 请求时,加入 NeedMVCC 这个标识字段即可:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 func (p *PhysicalTableScan) error ) { tsExec := tables.BuildTableScanFromInfos(p.Table, p.Columns, ctx.GetSessionVars().NeedMvcc) ctx.GetSessionVars().NeedMvcc = false } func BuildTableScanFromInfos (tableInfo *model.TableInfo, columnInfos []*model.ColumnInfo, needMvcc bool ) pkColIds := TryGetCommonPkColumnIds(tableInfo) tsExec := &tipb.TableScan{ TableId: tableInfo.ID, Columns: util.ColumnsToProto(columnInfos, tableInfo.PKIsHandle), PrimaryColumnIds: pkColIds, NeedMvcc: needMvcc, } }
接下来就可以交给 TiKV 来管了。对于 SQL 语句中的投影,选择等操作,无需修改,本身是兼容的。只要我们能够拿到想要的数据,构造好了想要的数据表 Schema,就可以实现剩余的功能。
其他 由于在后续 TiKV 读取行数据写入 MVCC 信息的实现中(见下文),采用了原始的简单编码方式(colID1 typed_value1 colID2 typed_value…),所以需要统一 TiDB 和 TiKV 的存储数据编解码方式。为了简单起见,我直接抛弃了 TiDB 新引入的编码方式:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 func EncodeRow (sc *stmtctx.StatementContext, row []types.Datum, colIDs []int64 , valBuf []byte , values []types.Datum, e *rowcodec.Encoder) byte , error ) { if len (row) != len (colIDs) { return nil , errors.Errorf("EncodeRow error: data and columnID count not match %d vs %d" , len (row), len (colIDs)) } return EncodeOldRow(sc, row, colIDs, valBuf, values) }
具体修改见:https://github.com/Long-Live-the-DoDo/tidb/pull/1 。
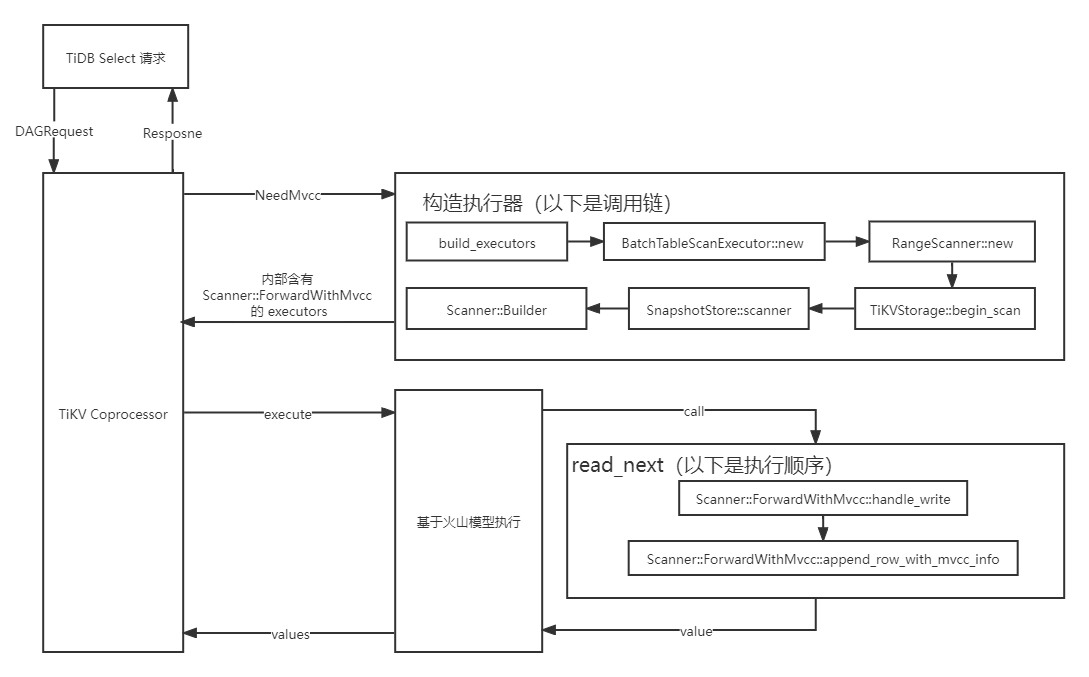
TiKV 侧实现 通过阅读 Coprocessor 的相关源码可以得知,整个 select 语句的执行过程可以大致拆分为:
构造 executor 及其中的 scanner
首先通过通过 build_executors 构造 executor。由于 select 语句对应的是 ExecType::TypeTableScan,所以相应的 executor 会通过 BatchTableScanExecutor::new 生成。而 build_executors 这里可以获取到 TiDB 发来的 RPC 请求,我们便可以从请求中提取出 NeedMvcc 字段传给 BatchTableScanExecutor 以便后续使用。
在 BatchTableScanExecutor 中,又会调用 ScanExecutor::new 生成一个 scanner wrapper。于是再将依次将 NeedMvcc 传递给 ScanExecutor 这个 wrapper。
由于 ScanExecutor 只是个 wrapper,所以它还会将内部的实际 scanner 定义为 RangeScanner 。于是再将 NeedMvcc 传递给 RangeScanner 保存起来。当之后 RangeScanner 执行 scan 逻辑时便可以获取到 NeedMvcc 了。
第一次 scan 时,RangeScanner 会通过会调用内部成员 storage 的 begin_scan 接口。而 RangeScanner 中的 storage 实际上是 TiKVStorage 。
在 TiKVStorage::begin_scan 中,又会根据 TiKVSttorage<S: Store> 的内部成员 store: S 的类型生成其对应的 scanner。这里的 store 其实是 SnapshotStore 。TiKVStorage 会通过 SnapshotStore::scanner 生成最终访问物理存储的 scanner。于是 NeedMvcc 就可以通过 begin_scan 函数调用传递给 SnapshotStore::scanner 构造相应的 scanner 了。
SnapshotStore::scanner 通过 ScannerBuilder 按照需求构造相应的 scanner。在原本的实现了两种 scanner:Scanner::Forward 与 Scanner::Backward,分别用于顺序和逆序扫描,并提供 next 接口返回每一次迭代读到的 Key-Value 值。于是我就知道了,我这里需要新增一个 Scanner::ForwardWithMvcc 来用于在顺序扫描中返回所有版本的 Key-Value。
我找到这条调用链其实是个逆序的过程,先找到最基本的 scanner,再向上溯源找到最基本的调用者。
scanner 迭代获取数据
构造完 executor 后就可以开始执行了。对于 select 也就是 TableScan 来说,对于每一行数据的读取实际上就是不断调用 ForwardScanner::read_next 这个方法(拿顺序遍历举例)。
read_next 方法会按照 Key 遍历 write 列族拿到 write 的值,然后再通过 handle_write 方法执行迭代器读取数据的实际逻辑。所以说,我们最终的目的就是为 Scanner::ForwardWithMvcc 实现它的 handle_write 方法。handle_write 的执行逻辑因 Scanner 采用的 ScanPolicy 而异。我们要实现的 WithMvccInfoPolicy 和原本的 Scanner::Forward 使用的 LatestKvPolicy 基本完全一致。LatestKvPolicy 遇到某 user key 的最新版本 value 时,会返回这个 value,并通过调用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 impl <S: Snapshot> ScanPolicy<S> for LatestKvPolicy { fn handle_write ( &mut self , current_user_key: Key, _: TimeStamp, cfg: &mut ScannerConfig<S>, cursors: &mut Cursors<S>, statistics: &mut Statistics, ) -> Result <HandleRes<Self ::Output>> { cursors.move_write_cursor_to_next_user_key (¤t_user_key, statistics)?; Ok (match value { Some (v) => HandleRes::Return ((current_user_key, v)), _ => HandleRes::Skip (current_user_key), }) } }
跳过这个 user key 之下所有之前的老版本。在 WithMvccInfoPolicy 下,我们并不采用这个逻辑,而是继续往下读。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 impl <S: Snapshot> ScanPolicy<S> for WithMvccInfoPolicy { fn handle_write ( &mut self , current_user_key: Key, commit_ts: TimeStamp, cfg: &mut ScannerConfig<S>, cursors: &mut Cursors<S>, statistics: &mut Statistics, ) -> Result <HandleRes<Self ::Output>> { cursors.write.next (&mut statistics.write); Ok (match value { Some (mut v) => { self .append_row_with_mvcc_info (&mut v, commit_ts, write_type)?; HandleRes::Return ((current_user_key, v)) } _ => { if write_type == WriteType::Delete { let mut v = vec! []; self .append_row_with_mvcc_info (&mut v, commit_ts, write_type)?; HandleRes::Return ((current_user_key, v)) } else { HandleRes::Skip (current_user_key) } } }) } }
WithMvccInfoPolicy 还有一点不同的是,遇到 Delete 的时,它也会返回一个 value。
WithMvccInfoPolicy 中的 handle_write 在返回 value 之前,还需要为 value 中添加入 _tidb_mvcc_ts 与 _tidb_mvcc_op 这两个虚拟列的数据。就像上面 TiDB 侧的实现中所说,这里采用了一种简单粗暴的编码方式,直接将 [colID, typed_value] 依次编码进最后的 value 字节数组中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 impl WithMvccInfoPolicy { fn append_row_with_mvcc_info ( &self , value: &mut Value, commit_ts: TimeStamp, write_type: WriteType, ) -> codec::Result <()> { codec::number::NumberEncoder::write_u8 (value, VAR_INT_FLAG)?; codec::number::NumberEncoder::write_var_i64 (value, EXTRA_MVCC_TS_COL_ID)?; codec::number::NumberEncoder::write_u8 (value, VAR_UINT_FLAG)?; codec::number::NumberEncoder::write_var_u64 (value, commit_ts.physical ())?; codec::number::NumberEncoder::write_u8 (value, VAR_INT_FLAG)?; codec::number::NumberEncoder::write_var_i64 (value, EXTRA_MVCC_OP_COL_ID)?; codec::number::NumberEncoder::write_u8 (value, COMPACT_BYTES_FLAG)?; codec::byte::CompactByteEncoder::write_compact_bytes ( value, &write_type.to_string ().as_bytes ().to_vec (), )?; value.shrink_to_fit (); std::result::Result ::Ok (()) } }
具体修改见:https://github.com/Long-Live-the-DoDo/tikv/pull/1 。
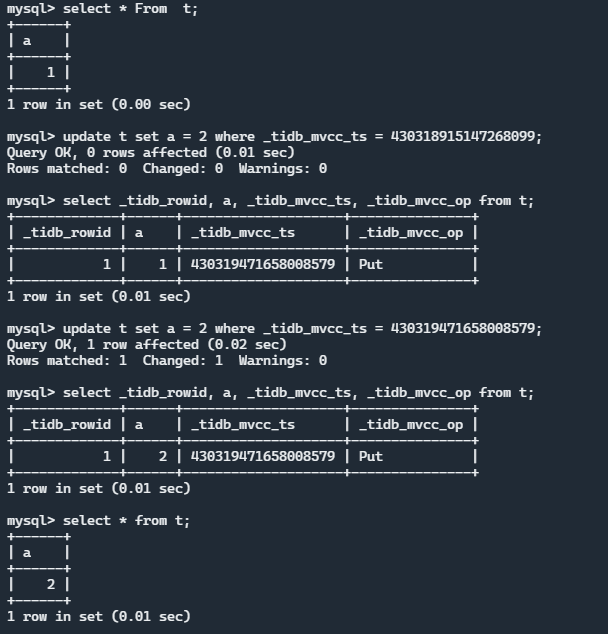
基于 MVCC 信息的 RawUpdate 功能 这个功能是一个附加的功能,比较好玩,实现上也非常的 hack。我们允许用户通过 SQL 语句来对某一个 Version 下的一条记录直接进行更改,也就是调用 TiKV 的 RawPut 接口,不进行事务相关的操作。
具体来说,当用户输入这样一个 SQL:
1 update t set a = 2 where _tidb_mvcc_ts = xxxx;
时,不会进行正常的 TiKV 的 KV 读写流程,也就是不会增加一条 Put 记录,而是在原来的记录上进行更改。
TiDB 侧实现 与 MVCC Query 类似,我们需要一个标识来表示这次是 RawUpdate,来让执行过程进入新的执行分支。这次是在构建 Plan 的时候往 Plan 里放一个标识字段:
1 2 3 4 5 6 7 8 9 10 11 12 13 func (b *PlanBuilder) error ) { updt := Update{ OrderedList: orderedList, AllAssignmentsAreConstant: allAssignmentsAreConstant, VirtualAssignmentsOffset: len (update.List), RawUpdate: b.ctx.GetSessionVars().NeedMvcc, }.Init(b.ctx) return updt, err }
这个参数会一直传递到物理计划的构建与执行中。然后就是具体的执行逻辑,这里的实现比较 hack。我是直接通过阅读 TiKV 源码后依葫芦画瓢在 TiDB 侧手动构造一个编码后的 Key 和 Value,然后通过 tikv/client-go 提供的 RawPutWithCF 接口直接进行写 KV 操作。使用 RawPut 不会进入 MVCC 事务流程,就相当于 KV 表的直接更新。
首先从旧的 row 中获取 MVCC 信息用于后续组装 Raw Key 和 Value:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 func (e *UpdateExec) error { commitTs := uint64 (0 ) op := byte ('P' ) if e.rawUpdate { for j, col := range schema.Columns { if col.ID == model.ExtraMVCCTsID { commitTs = row[j].GetUint64() } else if col.ID == model.ExtraMVCCOpID { op = row[j].GetString()[0 ] } } } changed, err1 := updateRecord( ctx, e.ctx, handle, oldData, newTableData, flags, tbl, false , e.memTracker, e.rawUpdate, commitTs, op) }
然后利用 MVCC 信息构造 Raw 请求:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 func (t *TableCommon) bool , commitTs uint64 , op byte ) error { key := t.RecordKey(h) encodedKey := codec.EncodeBytes([]byte {}, key) commitTsBytes := make ([]byte , 8 ) if commitTs == 0 { return nil } binary.BigEndian.PutUint64(commitTsBytes, ^commitTs) encodedKey = append (encodedKey, commitTsBytes...) sc, rd := sessVars.StmtCtx, &sessVars.RowEncoder value, err := tablecodec.EncodeRow(sc, row, colIDs, nil , nil , rd) if err != nil { return err } encodedValue := make ([]byte , 7 ) encodedValue[0 ] = op encodedValue[1 ] = 0 encodedValue[2 ] = 'V' binary.BigEndian.PutUint32(encodedValue[3 :7 ], uint32 (len (value))) encodedValue = append (encodedValue, value...) addrs := []string {"127.0.0.1:2379" } if store, ok := sctx.GetStore().(interface { EtcdAddrs() ([]string , error ) }); ok { if addrs, err = store.EtcdAddrs(); err != nil { return err } } cli, err := rawkv.NewClient(ctx, addrs, config.DefaultConfig().Security) if err != nil { return err } err = cli.PutWithCF(ctx, encodedKey, encodedValue, "write" ) if err != nil { return err } }
这里还有一个比较 hack 的点是,我直接将一行的值存放到了 write 里(因为不太容易拿到 start_ts 没办法构造 default 的 Key,为了可以容纳更多的数据,我在 write 里多加了一个 long value(类似于以前的 short value),具体实现见 TiKV。
具体修改见:https://github.com/Long-Live-the-DoDo/tidb/pull/3 。
TiKV 侧实现 TiKV 这边主要是依照 short value 给 write 增加了一个 long value。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 #[derive(PartialEq, Clone)] pub struct WriteRef <'a > { pub write_type: WriteType, pub start_ts: TimeStamp, pub short_value: Option <&'a [u8 ]>, pub long_value: Option <&'a [u8 ]>, pub has_overlapped_rollback: bool , pub gc_fence: Option <TimeStamp>, } impl WriteRef <'_ > { pub fn parse (mut b: &[u8 ]) -> Result <WriteRef<'_ >> { while !b.is_empty () { match b .read_u8 () .map_err (|_| Error::from (ErrorInner::BadFormatWrite))? { LONG_VALUE_PREFIX => { let len = b .read_u32 () .map_err (|_| Error::from (ErrorInner::BadFormatWrite))?; if b.len () < len as usize { panic! ( "content len [{}] shorter than short value len [{}]" , b.len (), len, ); } long_value = Some (&b[..len as usize ]); b = &b[len as usize ..]; } } } Ok (WriteRef { write_type, start_ts, short_value, long_value, has_overlapped_rollback, gc_fence, }) } }
然后在 handle_write 中添加相应的读取 long value 的逻辑即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 fn handle_write ( &mut self , current_user_key: Key, commit_ts: TimeStamp, cfg: &mut ScannerConfig<S>, cursors: &mut Cursors<S>, statistics: &mut Statistics, ) -> Result <HandleRes<Self ::Output>> { let (value, write_type): (Option <Value>, WriteType) = loop { match write_type { WriteType::Put => { if cfg.omit_value { break (Some (vec! []), write_type); } if let Some (value) = write.long_value { break (Some (value.to_vec ()), write_type); } match write.short_value { } } WriteType::Delete => break (None , write_type), WriteType::Lock | WriteType::Rollback => { } } } }
具体修改见:https://github.com/Long-Live-the-DoDo/tikv/pull/4 。
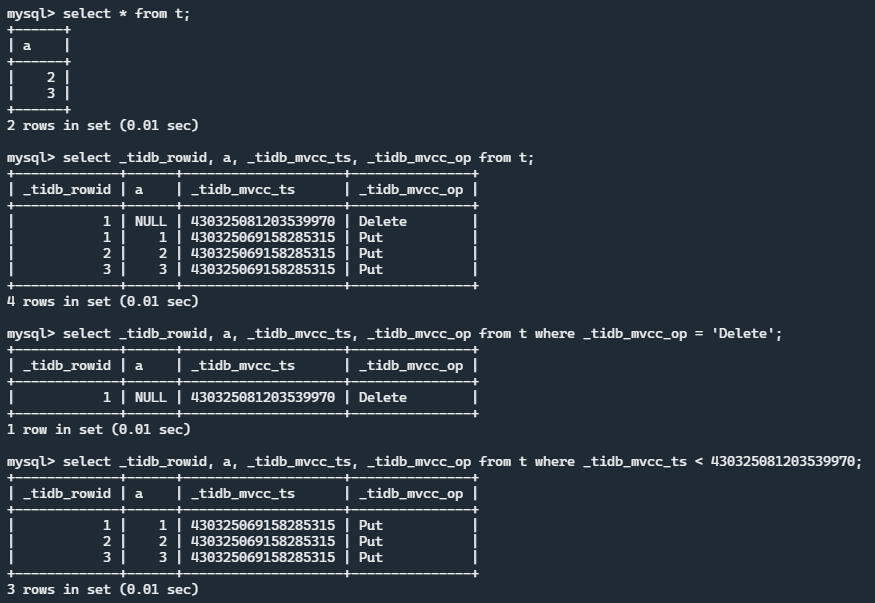
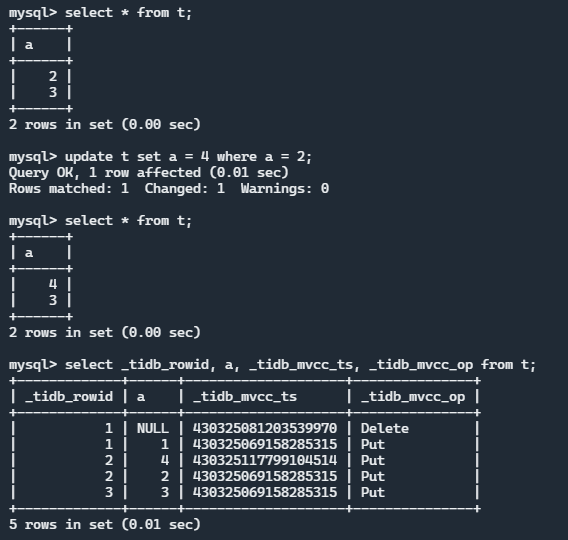
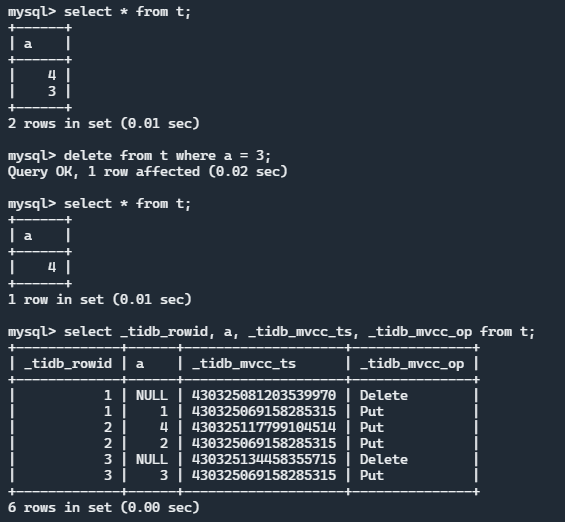
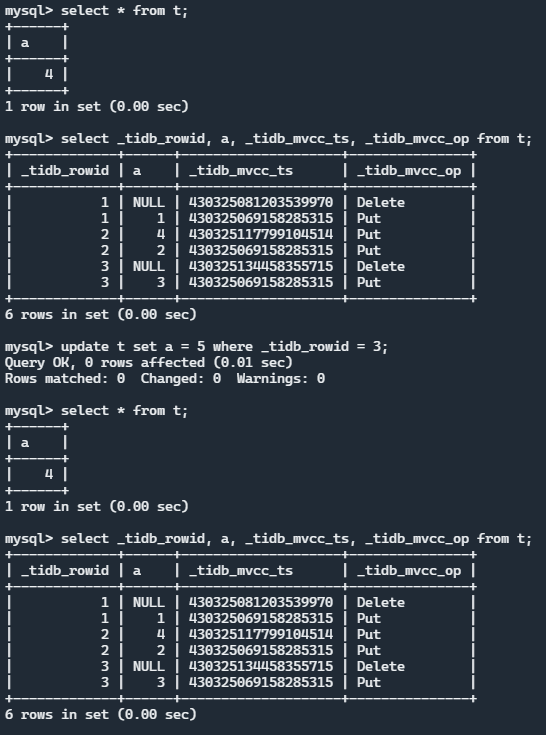
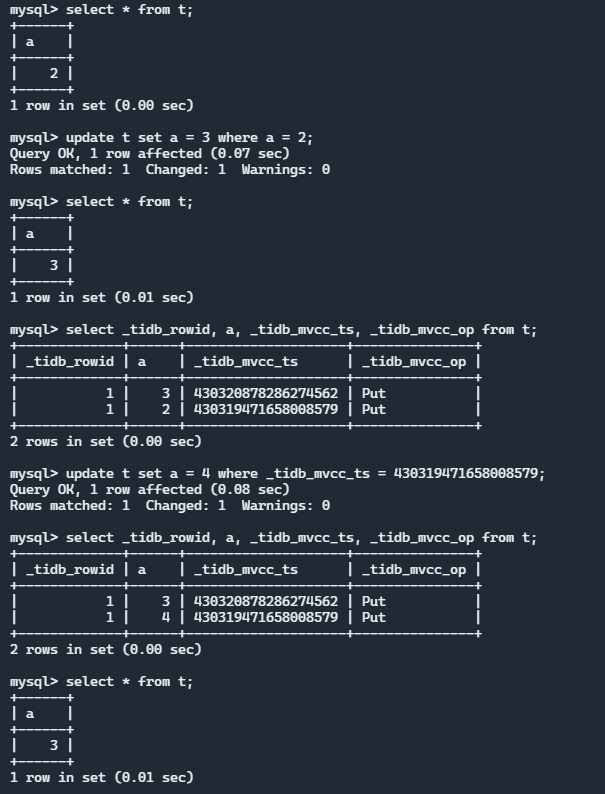
执行效果
还可以继续完善的点
将 NeedMvcc 存放在 SessionContextVars 中并不优雅,最好放入查询计划的相应结构中。
delete from t where _tidb_mvcc_ts=xxx 这样的语句存在二义性,后续可能会做成删除对应的 MVCC 记录。没有做 _tidb_mvcc_ts 与 _tidb_mvcc_op 相关的限制。例如,创建表时不允许以这两个名字命名、不允许修改这两列的值等。也可以做成,当修改这两列时直接进行 KV 更新操作(不过这种感觉没什么意义)。
在 TiKV 中只实现了 MVCC 的 ForwardScan 没有实现 BackwardScan,这可能造成某些使用了 BackwardScan 的语句的不兼容。
加入虚拟列的编码方式过于简单粗暴,可以考虑对其现阶段的 TiDB 适配所有编码方式。
只考虑了普通的 TableScan 操作,没有考虑 IndexScan。
这些操作只针对于单表单条语句,并不适用于多表与事务操作。
RawUpdate 操作不支持事务。
……
后话 在两位哥哥的带领下荣获三等奖。土豆哥的答辩片段:https://www.bilibili.com/video/BV1ZF411H73L