【ClickHouse 源码学习】线程池与后台任务
本文对 ClickHouse 代码中最重要的基础设置之一——线程池与后台任务框架进行了介绍,并总结了一些在 ClickHouse 二次开发中的经验教训。
现代的单进程程序软件通常会使用多线程来并行地执行多个任务,以达到提升性能、规避任务相互阻塞等作用。在 ClickHouse 中,多线程被运用于各个角落:比如一个查询的执行流水线会通过多线程并行执行多条数据流;Merge 任务会通过后台的一个独立线程来执行,而不会阻塞其他线程的任务等等。
然而,大家都知道,创建与销毁线程是存在开销的。因此在现代的系统中,都会引入线程池来优化线程的使用,让新的多线程任务直接复用已经创建好的线程。使用线程池主要有以下几个优点:
- 避免线程频繁地创建与销毁,减少线程创建与销毁带来的开销。
- 让系统能够限制与管理线程。
除此之外,ClickHouse 源码的注释中还提到以下几个优点:
- 复用线程能让 memory allocator 复用 thread local cache 以提升性能(尤其是 jemalloc)。
- 限制系统的线程个数能够让 address santizer 和 thread sanitzer 不会检查失败。
- 在 GDB 中程序能够运行地更快。
本文将会介绍 ClickHouse 的最重要的代码基础设施之一——线程池的设计以及基于线程池这一基础设施所构建的后台任务框架。
ClickHouse 在这里的设计层次分明、模块化清晰,值得学习。本文主要基于 ClickHouse 24.3 的代码进行学习。
线程池
实现原理
在 ClickHouse 中,线程池的实现抽象为了一个模版类:
1 | /// Pseudocodes |
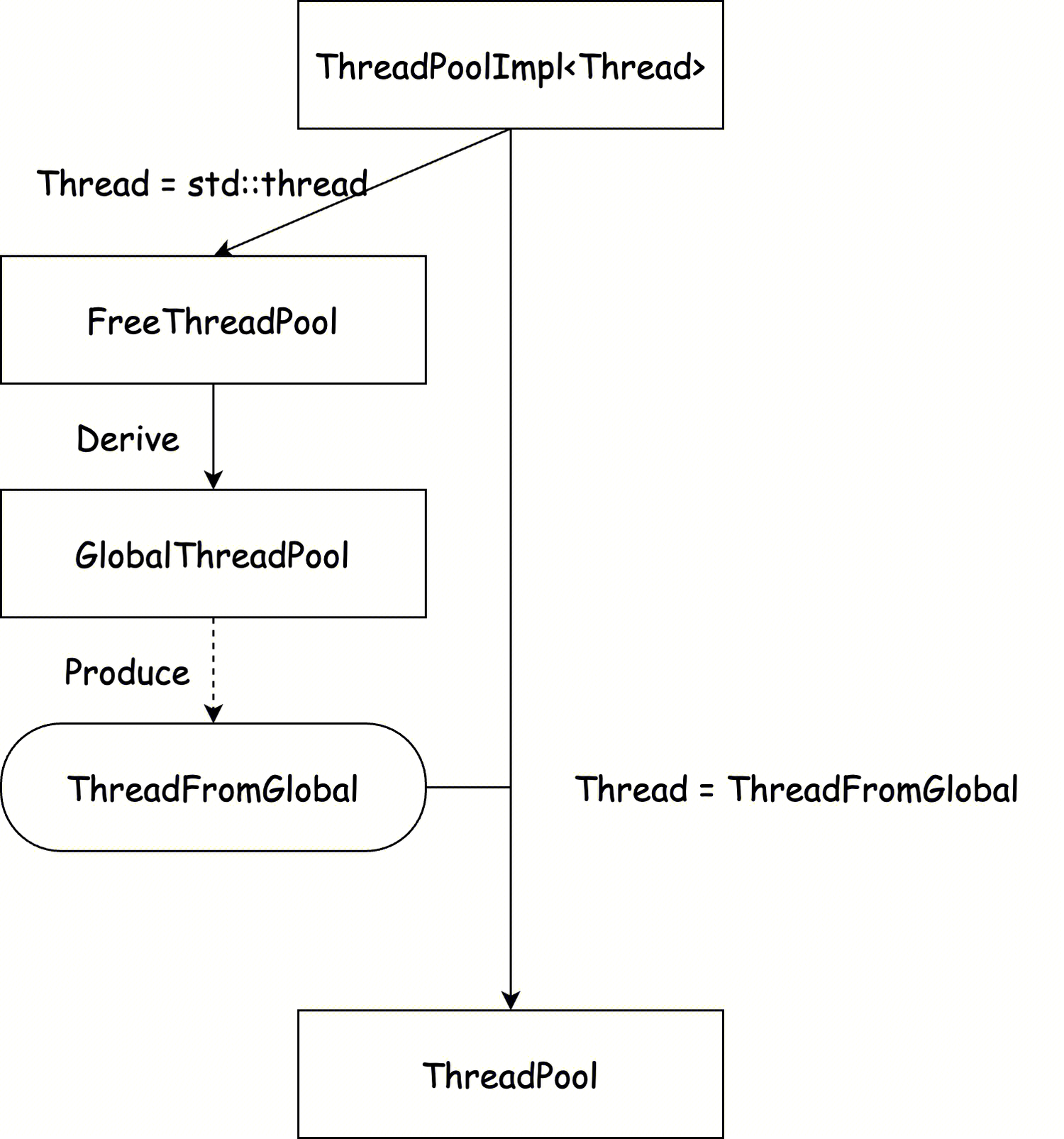
从定义上看,我们可以很容易猜到,线程池对象 ThreadPoolImpl 会生成并管理一批 Thread 实例,线程池的使用方可以将一个函数对象传给线程池进行调度,线程池将这个函数作为一个任务运行在其管理的某一个 Thread 实例上。ClickHouse 巧妙地将 Thread 作为了模板参数,来使用一套简洁代码分别实现了全局线程池与普通线程池,这将在后两节中介绍。
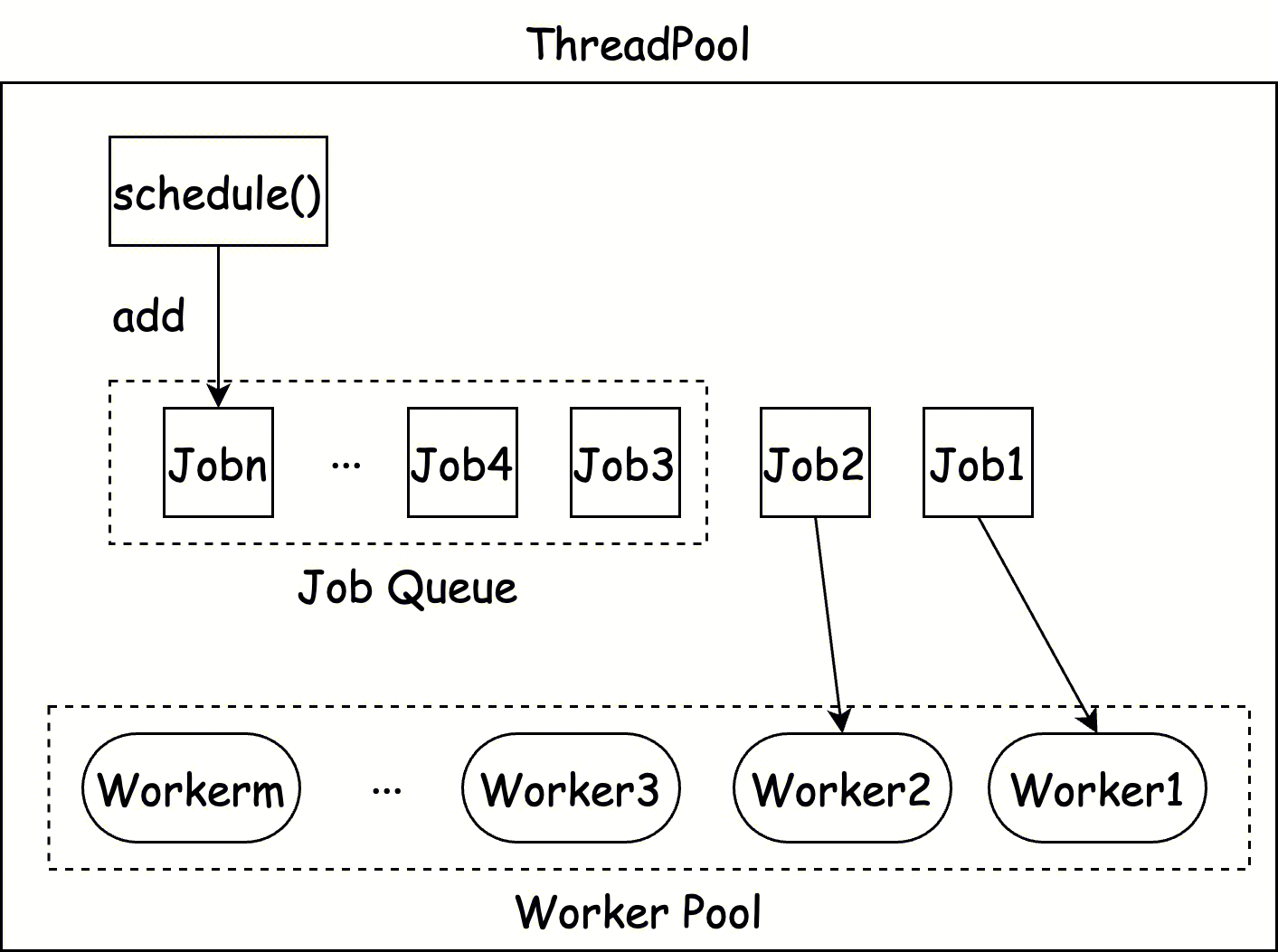
事实上,ClickHouse 在基础线程池的实现上确实也足够简单明了,其采用了经典的生产者与消费者结构,即线程池实例是生产者,线程池中管理的线程实例是消费者。线程池向任务队列中生产新的任务,线程实例从任务队列中消费任务并执行。依靠条件变量(condition varibale),线程实例在没有任务时进入睡眠状态(sleep),当有任务来时,线程池通知并唤醒一个线程实例(awake)来执行任务。ClickHouse 在线程状态的调度上并没有做过多的优化,而是完全交给操作系统内核来完成。
ClickHouse 线程池的消费者生产者实现大致如下伪代码所示,是一种经典的线程池实现范式:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113/// Producer
template <typename Thread>
void ThreadPoolImpl<Thread>::schedule(Job job)
{
{
std::unique_lock lock(mutex);
/// 等待空闲线程
auto pred = [this] { return !queue_size || scheduled_jobs < queue_size || shutdown; };
job_finished.wait(lock, pred);
/// 不是在线程池构造是一口气创建完所有线程,而是 lazy 地创建线程
if (threads.size() < std::min(max_threads, scheduled_jobs + 1))
{
try
{
threads.emplace_front();
}
catch (...)
{
/// 线程容器无法分配新的内存
}
/// 给创建出来的线程分配消费者
try
{
threads.front() = Thread([this, it = threads.begin()] { worker(it); });
}
catch (...)
{
/// 创建新的线程失败
threads.pop_front();
}
}
/// 将任务放入任务队列
jobs.emplace(job);
}
/// 唤醒一个空闲的 worker 线程
new_job_or_shutdown.notify_one();
}
/// Consumer
template <typename Thread>
void ThreadPoolImpl<Thread>::worker(typename std::list<Thread>::iterator thread_it)
{
bool job_is_done = false;
/// 线程消费者实现中常见的死循环
while (true)
{
{
std::unique_lock lock(mutex);
/// 结束当前任务
if (job_is_done)
{
job_is_done = false;
--scheduled_jobs;
job_finished.notify_all();
if (shutdown)
new_job_or_shutdown.notify_all(); /// `shutdown` was set, wake up other threads so they can finish themselves.
}
/// 等待新任务到来
new_job_or_shutdown.wait(lock, [&] { return !jobs.empty() || shutdown || threads.size() > std::min(max_threads, scheduled_jobs + max_free_threads); });
/// 如果没有设置 max_free_threads,则将线程释放掉
if (jobs.empty() || threads.size() > std::min(max_threads, scheduled_jobs + max_free_threads))
{
// We enter here if:
// - either this thread is not needed anymore due to max_free_threads excess;
// - or shutdown happened AND all jobs are already handled.
if (threads_remove_themselves)
{
thread_it->detach();
threads.erase(thread_it);
}
return;
}
job_data = std::move(const_cast<JobWithPriority &>(jobs.top()));
jobs.pop();
}
/// 执行任务
/// 每一个任务独占一个线程,具体的 CPU 调度交给操作系统完成
try
{
/// 运行任务
job_data()->job();
/// 任务执行完毕,销毁任务
job_data.reset();
}
catch (...)
{
/// 任务执行异常
job_data.reset();
}
job_is_done = true;
}
}
/// 为了保证线程池析构时所有资源都得到了释放,需要实现 wait 方法等待所有线程执行完毕
template <typename Thread>
void ThreadPoolImpl<Thread>::wait()
{
std::unique_lock lock(mutex);
/// Signal here just in case.
/// If threads are waiting on condition variables, but there are some jobs in the queue
/// then it will prevent us from deadlock.
new_job_or_shutdown.notify_all();
job_finished.wait(lock, [this] { return scheduled_jobs == 0; });
}
由于本文只关注线程与任务调度本身,上述伪代码中隐藏了不少关于任务优先级、异常、指标追踪以及线程池扩缩容的代码,感兴趣的同学请自行翻阅完整源码。
另外需要注意的是,线程池调度的任务定义为 std::function<void()>,因此一般调度的都是 lambda 函数,在使用时需要注意传给函数对象的变量的所有权与生命周期。
全局线程池
全局线程池(GlobalThreadPool)的实现非常简单,它就是上述的 ThreadPoolImpl<Thread> 将模板参数 Thread 特化为 std::thread 的版本,并采用单例模式提供给全局使用。ClickHouse 中的所有工作线程以及线程池都由这个全局线程池产生,其产生的就是实际的 std::thread。因此,全局线程池的容量很大,在默认情况下,全局线程池的容量为 10000(max_thread_pool_size),允许最大存活线程为 1000(max_thread_pool_free_size)。
普通线程池
在 ClickHouse 中,不同的模块可能有单独的多线程任务,为了给这类任务也限制线程使用量,ClickHouse 提供了区别于全局线程池的普通线程池(ThreadPool)。为了让系统的总线程数可控,普通线程池并不是另起炉灶,重新生成新的由自己管理的线程,而是从全局线程池中派生。换句话说,普通线程池是中的线程是全局线程池线程的子集。
ThreadFromGlobal
正如前文所说,ClickHouse 通过类 ThreadPoolImpl<Thread> 将所有种类的线程池用一套代码实现,使得全局线程池和普通线程池都具有同样的线程调度逻辑。那么解法也就显而易见了,那就是普通线程池需要实现一种新的 Thread 来特化 ThreadPoolImpl,而这种 Thread 只需要是从全局线程池中产生即可。而 ClickHouse 的实现正是如此:
1 | template <bool propagate_opentelemetry_context = true> |
上面这个 ThreadFromGlobalPoolImpl 的重点便是它的构造函数,剩下的便是对其一些 ThreadPoolImpl 中需要用的线程接口即可(如 join、detach、joinable、get_id 等)。ThreadFromGlobalPoolImpl 的实现很直观简单,就是将需要调度的任务函数转发给全局线程池进行调度,并通过一个 State 结构体来记录当前线程的状态。
其他
ThreadStatus 与 CurrentThread
为了统计记录一条查询中每个线程的相关统计信息,ClickHouse 定义了 ThreadStatus 类,记录了 CPU、内存以及查询读写的相关统计信息。并通过 thread_local 关键字为每一个线程实例化一个 ThreadStatus 对象。
1 | /** |
通过静态类 CurrentThread(只有静态方法)可以对此变量进行操作。比如获取此线程的一些统计信息等。
ThreadGroup
ThreadGroup 类的作用是将多个线程汇聚在一起进行统计,一般用于同一类任务统计信息的整体统计,比如统计一个查询的所有线程的资源使用量。
后台任务
在数据库系统中存在着大量的后台任务,比如在 ClickHouse 中,Merge、Mutation、副本表的数据同步以及各种周期性的任务都是在后台线程中异步执行。这样的后台任务也和线程一样不能无限膨胀,需要有一定调度机制来保证系统处在一种安全运行的状态。所以这样的任务和线程池一样,需要有一个运行时(Runtime)来对它们进行调度。
在实现这样的调度器时,和实现线程池一样,我们往往需要主线程中的 while true 死循环来处理处理与分发任务,利用条件变量来睡眠与唤醒线程,来高效利用操作系统资源。ClickHouse 的代码基础设施中已经封装好了这样一套框架供开发者使用,就是接下里介绍的 BackgroundSchedulePool 与 MergeTreeBackgroundExecutor。
BackgroundSchedulePool
BackgroundSchedulePool,顾名思义,后台调度池,如果你存在这么一个任务,它同一时刻只会有一个线程在运行,并且你可以在你想要的时候随时唤醒它让它执行;又或者你想创建一个周期性执行的任务,那么在 ClickHouse 中,你可以使用 BackgroundSchedulePool 来实现这个功能。BackgroundSchedulePool 中最主要的结构是它的 worker 线程与任务队列,其定义如下所示:
1 | class BackgroundSchedulePool |
这个类提供 createTask 方法,其接受一个函数并将其封装在一个任务类中(就是下文介绍的 BackgroundSchedulePoolTaskInfo),上层应用可以随时激活或取消激活此任务。当激活并调度任务时,BackgroundSchedulePool 的 Runtime 会执行这个任务中封装的函数。
它的调度器实现得非常简单,就是用条件变量监听任务队列,当有新任务时,获取任务执行。
1 | void BackgroundSchedulePool::threadFunction() |
除了这个主任务线程之外,它还有一个延迟任务线程。因为 BackgroundSchedulePool 中的任务还可以指定一段时间之后再运行,这样的任务申请被调度时,就会被放入延迟任务队列,然后由延迟任务线程提取执行。延迟线程的实现和主线程类似,只是多了一些延迟等待逻辑。BackgroundSchedulePool 另外一个重要的接口为 scheduleTask,它接受一个 task(下文的 BackgroundSchedulePoolTaskInfo 类),并将其放入任务队列,并由上文所述的 runtime 获取执行。
1 | void BackgroundSchedulePool::scheduleTask(TaskInfoPtr task_info) |
BackgroundSchedulePoolTaskInfo
这个类其实就是对想要执行的函数的一层封装,它由一个 std::function<void()> 构造,并封装了一些列方法来与 BackgroundSchedulePool 进行交互。这个类的主要作用是为了将用户想要执行的任务封装为一个有状态的对象,其可有如下几种状态:未激活(deactivated)、激活(activated)、已被调度(scheduled)、已被延后(delayed)、执行中(executing),并由一个简单的状态机进行驱动,以保证同一时刻这项任务只会被执行一次。BackgroundSchedulePoolTaskInfo 只有在被激活的时候才能够被调度,只有在空闲的时候能够被执行,开发者可以基于这两个基础来设计自己的后台任务调度逻辑。
此类主要有两个调用方,一个是任务发起方,一个是任务调度器 BackgroundSchedulePool。任务发起方主要调用 schedule 函数(以及其变体 scheduleAdfter)将任务放入任务队列,任务调度器则是调用其 execute 函数进行函数的实际执行。
1 | bool BackgroundSchedulePoolTaskInfo::schedule() |
通过锁的使用,保证了同一时刻同一个 task 只会有一个在执行。
1 | void BackgroundSchedulePoolTaskInfo::execute() |
使用案例
MergeTree 引擎后台任务分配器 BackgroundJobsAssignee、DatabaseCatalog 的后台周期性清理任务以及下文提到的 MergeTreeBackgroundExecutor 等。
MergeTreeBackgroundExecutor
MergeTree 后台执行器 MergeTreeBackgroundExecutor 是另外一种后台调度模型/框架,它基于上述 BackgroundSchedulePool 实现。它的用途简单直接:接受并执行后台任务。也就是说,我们向这个结构提交一个任务,它就可以帮我们在后台执行此项任务。MergeTreeBackgroundExecutor 存在一个有容量限制的调度队列,按照 Round-Robin 或者优先级调度的方式来执行提交到它的任务。MergeTreeBackgroundExecutor 的实现于 BackgroundSchedulePool 大同小异,都会暴露一个 schedule 方法,将任务放入队列,并存在一个 runtime 调度这些任务并进行执行。与 BackgroundSchedulePool 不同的是,MergeTreeBackgroundExecutor 的任务数量存在上限,如果任务数量已满,会调度失败;另外,MergeTreeBackgroundExecutor 中的任务可以按照 Round-Robin 的策略进行调度,也可以按照一定优先级进行调度,取决于它们的调度队列容器使用的是普通队列还是优先队列(堆)。这里就不贴代码了,感兴趣的同学可以自行查看。
虽然基本的调度框架类似,但是 MergeTreeBackgroundExecutor 和 BackgroundSchedulePool 执行任务存在一些差别。BackgroundSchedulePool 每一次调度任务都会把整个任务执行完毕;而 MergeTreeBackgroundExecutor 允许任务可以分步执行,每一次调度只执行任务的一个步骤,执行完一个步骤重新放入任务队列等待下一次调度,当任务的所有步骤都执行完毕,将执行其 onComplete 方法,这一点与 ClickHouse 的计算 Pipeline 模型类似。MergeTreeBackgroundExecutor 的任务由一个抽象类进行定义:
1 | class IExecutableTask |
只要实现了这个抽象类,便可以被 MergeTreeBackgroundExecutor 执行,其主要方法即是 executeStep() 这个方法,它将在任务每一次调度是被执行。当其返回 false 时,表示任务已经被执行完毕,再执行一次 onCompleted 方法后即被销毁。也就是说,与可以重复执行的 BackgroundSchedulePoolTaskInfo 不同,IExecutableTask 提交后只会被执行一次。
BackgroundJobsAssignee
MergeTreeBackgroundExecutor 主要是和 BackgroundJobsAssignee 这么一个类进行配合。MergeTree 族的引擎会通过 BackgroundJobsAssignee 提交后台任务给 MergeTreeBackgroundExecutor 执行。其主要在 MergeTree 族引擎的后台任务分发方法 scheduleDataProcessingJob 中被执行,在这个函数中,会调用 BackgroundJobsAssignee 封装的任务提交方法,间接调用 MergeTreeBackgroundExecutor 的任务调度方法,比如:
1 | bool BackgroundJobsAssignee::scheduleMergeMutateTask(ExecutableTaskPtr merge_task) |
如果调度成功,会使用 trigger 方法立刻再进行一次 scheduleDataProcessingJob,如果调度失败,则会使用退避算法延后 scheduleDataProcessingJob 的执行。这样一个执行框架保证了 MergeTree 族引擎能够在新数据产生时及时处理这些数据,执行 Merge、Mutation 以及从其他节点 Replicate 数据等操作。
使用案例
提交异步执行 Merge、Mutation 任务以及副本表同步任务等。
DIY
当然,如果我就是想拥有一个不受调度器控制的后台任务,想让这个任务在逻辑上一直处于运行状态,我们也可以选择自己从 ThreadPool 中创建一个线程(ThreadFromGlobalPool)出来,自行写一个 while true 循环,通过手写条件变量与 std::sleep 语句来实现自己的逻辑。
使用案例
服务发现模块 ClusterDiscovery 等。
开发中需要注意的点
在对 ClickHouse 的二次开发中,我们会频繁地使用上述的这些代码基础设施,但是第一次使用时都难免会踩到一些坑,或者说,光看方法名无法注意到的细节。本节总结了两个比较常见的坑。
线程名长度限制
ClickHouse 中设计了 setThreadName 方法(位于 src/Common/setThreadName.h/cpp )来为当前线程设置自定义的名字,其中会根据系统不同使用不同系统调用。以 Linux 系统为例,它会调用 prctl 方法,并使用 PR_SET_NAME 选项对线程进行命名,其中这个方法限制线程名只有 16 个字节[2](包括最后的 ‘\0’,即实际只能有 15 个字符),如果超过会对其进行截断。ClickHouse 的实现在这上面更近一步,会首先判断名字是否大于了 15 个字符,如果超过,会抛出异常。
1 |
|
于是乎,这里就引来的第一个坑点,那就是如果我们不知道这个限制贸然地给线程设置了超过 15 个字符的名字,这个线程可能会默默地消失,我们察觉不到任何异常——因为它一般是在一个独立的线程中被调用,我们根本没有捕获它的异常!而这个线程就这样因为抛出异常自己结束了自己的一生。
这个问题会影响另外一个重要的组件:BackgroundSchedulePool。BackgroundSchedulePool 在构造的时候我们会给它赋予名字,而这个名字正是用来 setThreadName 的。而在使用 BackgroundSchedulePool 还有一个坑点,那就是它除了会创建名字为 ‘{name}’ 的主线程外,还会创建名字为 ‘{name}/D’ 的延迟任务线程,而这个名字也需要受到 15 个字符的限制。因此,BackgroundSchedulePool 的名字最多只能有 13 个字符。
当你发现在创建了 BackgroundSchedulePool 但它并没有起任何作用时,首先去检查一下是不是给它的名字其对了没!
在去年 12 月的 PR #58310 中,对这个函数增加了 truncate 的参数,可以让其不抛异常而是和系统调用一样截断名称,不过这个参数默认为 false,所以我们在使用这个方法的时候还是需要注意。
后台任务不一定能调度成功
我们在使用 BackgroundSchedulePoolTaskInfo 或者 MergeTreeBackgroundExecutor 的时候我们会发现,他们的调度方法(BackgroundSchedulePoolTaskInfo::schedule 与 MergeTreeBackgroundExecutor<Queue>::trySchedule)的返回值为 bool 而不是 void,这说明他们的调度是可能成功可能不成功的。前者只有在自己这项任务在 active 状态以及没有正在被调度的时候才会成功;后者只有在任务池中任务数量没有达到上限时才会成功。
因此。我们在利用这两个结构进行后台任务调度的时候要注意,我们提交的任务可能是没有进入调度队列的,如果我们的逻辑是想要这个任务一定会被调度成功,还需要有额外的处理逻辑。
不足之处
ClickHouse 拥有一个设计完备的线程池模块,但是在实际使用中,我们很容易发现同一时间对 ClickHouse 的请求稍微一多(多个客户端并行读写),ClickHouse 的性能就会急速下降。ClickHouse 在执行任务时,会尽可能的把所有资源都利用上,比如在一个 32 核的机器上,不同的两个查询都会创建并行度为 32 的流水线执行任务,而这些执行任务的线程都会由 ClickHouse 的全局线程池产生。当并行的任务暴涨时,线程池的瓶颈很容易成为整个系统的性能瓶颈。而 ClickHouse 在线程池这里确实存在设计缺陷。
好巧不巧的时,几个月前,Altinity 的一位哥们儿刚好也对 ClickHouse 线程池缺陷进行了分析,并进行了优化,详细细节可以看他的文章[3]。简单总结来说就是,ClickHouse 原本的线程池是在持有锁的时候创建的线程,而这一过程完全可以移到锁之外。他的本次优化使 ClickHouse 的 QPS 提升了 10%,并且大幅度降低了锁的开销。本次优化已经在 ClickHouse 24.10 中发布。