关于 LevelDB 的一些问题(个人向)
记录一下学习 LevelDB 遇到的一些问题。
最后更新:2022-05-08。
为什么每次重新打开 LevelDB 都会生成新的文件
如果一开始就不存在 DB 相关文件,自然会创建新的,这里主要看一下已经存在旧的文件时的情况。
MANIFEST 文件
先来看 MANIFEST 这个文件为什么每次都会生成一个新的。在方法 DB::Open 中,会调用方法 DBImpl::Recover(VersionEdit* edit, bool* save_manifest) 将 DB 信息恢复到内存中,其中的参数 save_manifest 就代表这是否需要将内存中的元信息写入到新的 MANIFEST 文件中。
首先会进入到方法 VersionSet::Recover(bool* save_manifest) (db/version_set.cc) 中。这个方法会读取老的 MANIFEST 文件,恢复整个 DB 的元信息(比如 comparator name、log number、last seq number、new file entry 等)。在方法的最后,会调用 VersionSet::ReuseManifest 来判读是否需要重新生成新的 MANIFEST 文件:
- 如果
Options中没有设置reuse_logs这个选项,则默认会生成新的 MANIFEST 文件 (return false)。 - 否则会进行一系列的信息检测,如果都通过,则会不会生成新的 MANIFEST 文件 (
return true)。这些检测包括:- 当前的 DB 文件是否都合法。
- 当前的 MANIFEST 是否是 appendable 的。
回到 DB::Oepn 后若 save_manifest 为 true,则通过 VersionSet::LogAndApply 写入新的 MANIFEST 文件。然后再调用 DBImpl::RemoveObsoleteFiles 来删掉旧的 MANIFEST 文件。
涉及 MANIFEST 文件的伪代码大致如下:
1 | // db/db_impl.cc |
.log 文件
每次重启 DB 都会生成新的 .log 文件,但是创建时机有所不同。
最简单的是,旧的 .log 文件中没有记录,所以在之前的 DBImpl::Recover 过程中不会建立 MemTable,也就是 impl_->mem_ 为 nullptr,程序会以这个依据在 DB::Open 的逻辑中为 DB 创建新的 .log 文件并在内存中创建新的 Memtable。
如果旧的 .log 文件有记录,则会在 DBImpl::Recover 中调用的 DBImpl::RecoverLogFile 中读取记录,并在这个时候建立 MemTable,并将 log 应用到 MemTable 中,并立刻持久化到 .ldb 文件中(minor compaction)。这里并不会将创建的 MemTable 保存在内存中(也就是不会赋值给 impl_,因为需要将已经落盘的 MemTable 从内存中丢弃),等逻辑回到 DB::Open 中后,会和上面所说的 .log 中没有记录一样,进入 impl->mem_ == nullptr 的逻辑,统一创建新的 .log 文件与 MemTable。
顺带一提的是,其实可以设置 Options 中的 reuse_logs 选项来选择复用旧的 .log 文件,但是前提是 .log 是 appendable 的,并且没有经历过 compaction(如果 MemTable 中的数据量过大,会在判断 reuse_logs 选项之前进行 minor compaction,将 MemTable 落盘,需要将已经落盘的 MemTable 从内存中丢弃,这之后就会进入上面所说的创建新 log 的逻辑,所以就没法复用旧 log 了)。如果没有经历过 compaction,则可以直接保留 MemTable 到 impl_->mem 中,跳过之后创建新 log 和新 MemTable 的逻辑。
最后与 MANIFEST 文件同理,会通过 DBImpl::RemoveObsoleteFiles 清理掉旧的 .log 文件。这里需要注意的是,一旦 Recover 了 log 并 dump 到了 SST 之后,旧的 log 就作废不能再使用了,必须将其删除,如果在上述 reuse_logs 的逻辑中继续使用经历过 minor compaction 的 log,则会导致再次重启时重复写入已经 dump 过了的大量数据,影响性能。
涉及 .log 文件的恢复流程大致伪代码如下:
1 | // db/db_impl.cc |
.ldb 文件
如上文所说,在重新打开 DB 后,如果旧的 .log 文件中存在写入记录,则会根据 log 建立 MemTable,并调用 DBImpl::WriteLevel0Table 将刚建立 MemTable 写入(或称 dump)为一个新的 .ldb 文件,并将 MemTable 删除。值得注意的是,这里虽然方法名字叫 WriteLevel0Table,但是其实不一定是写到 Level-0,LevelDB 可能会按照一定策略提前将 SST 写到更深层的 Level 中,这部分留到之后再看了。如果 log 中没有相关记录则不会创建新的 .ldb 文件。这个 .ldb 文件也就是 SST,是对某一时刻的 MemTable 的 dump,也就是说一般情况下都是只读的。
在 DB::Open 的最后,还会调用 DBImpl::MaybeScheduleCompaction 在后台开启负责 compaction 的线程,对满足条件的 .ldb 文件进行 major compaction,这部分也留到之后再看。
DBImpl::Write 中为什么要调用 Sync()
如果 WriteOptions 中设置了 sync 选项,在写入 log 之后会立刻调用 logfile_->Sync():
1 | status = log_->AddRecord(WriteBatchInternal::Contents(write_batch)); |
我的疑惑是 AddRecord 的实现中已经调用了 write 将内容写到了对应的文件描述符对应的文件,为什么还需要 Sync?这里其实是因为现代操作系统一般执行写入的时候都只是先把内容写到缓存中,极其一定大小的数据块后才统一 flush 到磁盘中,这样加快了写操作的速度。而调用 Sync 就相当于强制刷盘,进行一个同步的等待。拿实现了 POSIX 接口的环境来说(执行逻辑进入 util/env_posix.cc),最终会调用 fcntl(fd, F_FULLFSYNC) 或 fdatasync(fd) 或 fsyn(fd) ,这取决于当前系统的支持,其目的都是进行一个强制落盘的同步操作。所以说开启了 sync 这个选项可能使写操作变慢。如果 Sync 失败,则会记录一个 bg_error_(background error),使得之后所有的写操作都失败,源码中的注释写的是:
The state of the log file is indeterminate: the log record we just added may or may not show up when the DB is re-opened. So we force the DB into a mode where all future writes fail.
我也不知道进入这个失败模式后会不会通过一些措施恢复,针对 bg_error_ 搜索了一番发现并没有恢复的逻辑,可能进入这个模式之后就只能靠应用层重启 DB 了吧。
DBImpl::Write 是怎么使用 writers 队列的
一开始这个 writers 队列,还有 writer 的 condition variable 还有最后的 while 循环 pop writers 队列的一系列操作看的我很懵逼,心想这到底有什么意义,看起来和加一把大锁串行执行没什么区别。理解这一段代码着重需要理解这两个东西:
- C++ 中 condition variable 的用法。
DBImpl::BuildBatchGroup(Writer** last_writer)这个方法的作用。
对于 condition variable 的实现,正好在 6.S081 中才学习到过,所以印象还算深刻。这里用到了 C++11 引入的 condition_variable,以及它的两个方法 wait 和 notify_one,其中 wait 的作用是让当前线程进入睡眠,指导有另一个线程调用了 notify_one(或 notify_all)唤醒它。这里有一个要点是 wait 还接收一个 lock,因为它会在进入睡眠之前 release 这个 lock,并在被唤醒后重新 acquire 这个 lock,如果一个 sleep 了的线程 hold 一个 lock,那不就一直死锁了嘛,至于为什么需要这样一个锁,那是因为 condition_variable 的操作往往通常出现在加锁的逻辑中(也就是需要对共享内存进行并发原子操作的场景),关于 condition_variable 更具体地细节可以查阅 https://en.cppreference.com/w/cpp/thread/condition_variable 。
对于 DBImpl::BuildBatchGroup(Writer** last_writer) 方法,不看的话还真会忽略掉一个最重要的东西,那就是在这个方法会将当前 writers 队列中的所有 writer 构建为一个 WriterBatch,并将 last_writer 更新为最后一个 writer(但是有个例外是,带了 sync 选项的不会和不带的一起)。
现在再来看着一段代码就很清晰了:
1 | Status DBImpl::Write(const WriteOptions& options, WriteBatch* updates) { |
首先 MutexLock l(&mutex_); 这段代码会先锁定 mutex_(类似 scoped_lock),最开始由于锁的存在只会进入一个 writer,并且不会进行 wait。当这个 writer 构建 WriteBatch 完毕之后便可释放 lock(因为每一个 WriteBatch 的落盘是互不影响的,它们之前没有需要共享的数据,MemTable 也有自己的锁)。在 lock 释放后并执行写入的这段时间,其他等待的 writer 便可以进入之后的被 push 进 writers 队列并进入睡眠状态。前一个 WriteBatch 的写入时间越长便越能积累更多的 writer。当前一个 WriteBatch 执行完毕后,就会查看 writer 队列,并唤醒一个 writer。下一个 writer 便可以同时将当前队列中的所有 writer 构建为一个 WriteBatch,并将 last_writer 更新为最后一个 writer。之后的 while 循环便是将已经被统一操作的 writer pop 出队列,并结束它们 block 住的线程。
DBImpl::Write 的设计让我在数据库写操作的设计与 C++ 多线程编程上学到很多(太棒了,学到昏厥)。代码逻辑清晰,可读性强,注释完备,连我那么菜的人都能轻松读懂,LevelDB 的代码质量可见一斑。
何时触发后台 Compaction
直接查看 DBImpl::MaybeScheduleCompaction 这个方法的调用地点:
DB::Open完成之后会立刻进行一次。- 在
Get操作中,如果查找进入到了 SST 文件中,并将此文件的allowed_seek数量耗尽,并且没有其他正在 compact 的文件,便会将此文件设置为即将 compact 的文件并尝试启动后台 compaction 线程。 - 通过
DBIter迭代时,会设定一个bytes_until_read_sampling_,这个值是 0 ~ 1MB 中的一个正态分布随机值,如果迭代的数据量达到了这个上限,便会进行一次 sampling 操作,统计 SST 的读取统计信息,和上面的Get操作类似,如果某 SST 的allowed_seek耗尽,便会尝试启动后台 compaction 线程。 Put与Delete操作最终会调用DBImpl::Write。调用DBImpl::Write时会首先调用DBImpl::MakeRoomForWrite为写操作预留空间。在此方法中,如果发现 mutable 的MemTable已满,则会将它变为 immutable,然后创建新的 mutableMemTable,并尝试启动后台 compaction 线程。
现在再来看看 DBImpl::MaybeScheduleCompaction。对于一个 DB,只会产生一个 compaction 线程。具体来说,后台会启动一个 background_thread 线程,作为调度器,它的作用是循环抽取后台任务队列 background_work_queue_ 中的任务进行执行(如果队列为空会进入 wait 状态,有新的任务到来时再被唤醒),后续调用 DBImpl::MaybeScheduleCompaction 便会向任务队列推入一个 compaction 任务而不产生新的线程。这里我有一个疑惑是,源代码中是先进行唤醒,再向任务队列中放任务:
1 | // util/env_posix.cc |
是否先 emplace 再 Signal 更好,比如:
1 | void PosixEnv::Schedule( |
但是其实这里并没有问题,先看看 background_thread 执行的代码:
1 | void PosixEnv::BackgroundThreadMain() { |
这里 background_work_cv_ 条件变量中的的 mutex 就是 background_work_mutex_,就像上一节「DBImpl::Write 是怎么使用 writers 队列的」中所说,从 wait 中苏醒后会立刻给 mutex 重新调用 lock,所以这里如果 background_thread 在 Schedule 的途中被唤醒,它并不会直接继续向下执行,而是会等待任务被推入队列然后释放锁之后才会进入后面的逻辑。
compaction 的调用链为 DBImpl::BGWork -> DBImpl::BackgroundCall -> DBImpl::BackgroundCompaction。
Compaction 的整个流程是怎样的
Minor Compaction
首先,在启动后台 compaction 线程后,如果发现存在 immutable MemTable,会立刻调用 DBImpl::WriteLevel0Table 将其 compact 到 Levels 中。这里有一点需要注意的是,新的 mutable MemTable 与 log 文件已经在将 mutable 变为 immutable 的时候进行了,所以在 DBImpl::WriteLevel0Table 成功之后可以直接设置新的 log number 并进行 VersionSet::LogAndApply 持久化最新的 DB meta 信息,并 DBImpl::RemoveObsoleteFiles 删除旧文件。
这里来仔细看一下 DBImpl::WriteLevel0Table,虽然名字是写 Level-0 的 SST,但是实际上不一定,它通过 Version::PickLevelForMemTableOutput 来确定新写的 SST 应该属于哪一层。这里借用博主 beihai 博客中的一张图来表示应该选用哪一层(最多到 Level-2):
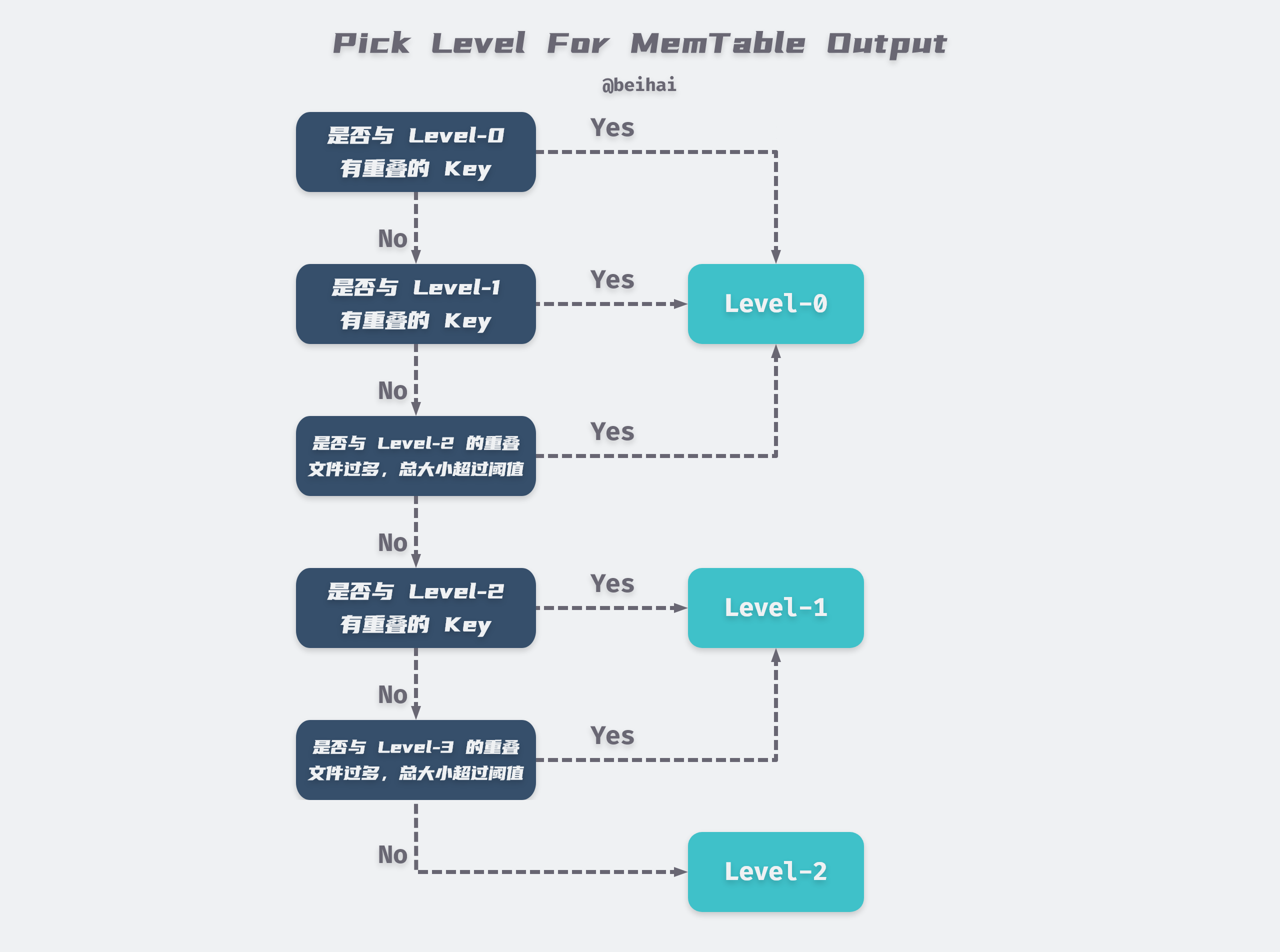
图中最下面的阈值是指,重叠的文件总大小大于 10 倍的 max_file_size(默认是 2MB)。
这里值得注意的一点是,代码逻辑中,是先写好 SST(落盘),再为它选择 Level。进行完 minor compaction 之后,本次 compaction 任务就结束了,不会再继续进行 major compaction。下一次 compaction 得等到下一次 DBImpl::MaybeScheduleCompaction 的触发。
Major Compaction
如上一小节所说,LevelDB 中,Minor Compaction 和 Major Compaction 不会在一次 compaction 中一起完成。也就是说进行 Major Compaction 的时候 immutable Memtable 还是空的。
LevelDB 还提供了手动 compaction(ManualCompaction)的功能,这里主要看自动的部分。首先来看 VersionSet::PickCompaction 方法,这个方法会生成 Compaction 对象,供正式 compaction 使用。这里会有两种策略,一种是 size_compaction,一种是 seek_compaction,前者优先,并且一次只能选择一种 compaction,如果两种策略都不能执行,则不进行 compaction。size_compaction 的依据是 compaction_score 是否大于 1,这个值会通过 VersionSet::Finalize 这个方法进行评估,这个方法会得出需要 compaction 的 level 与 compaction_score,具体留到后面再看;seek_compaction 就是前面提到过的,对一个文件的 Get 和 DBIter 操作数达到上限后会设置这个文件为需要 compact 的文件(file_to_compact)。
对于 size_compaction,如果是启动后第一次进行 compaction,则选择该 level 的第一个文件。如果之前该 level 已经经历过 compaction 了,那么在 VersionSet::compact_pointer_[level] 中会存下上一次的 compaction 的最后一个 key ,本次 compaction 会选择此 key 之后的第一个文件,更准确地来说,会选择该 level 第一个最大 key 大于 compact_pointer_[level] 的文件;如果不存在这样的文件,则选择该 level 的第一个文件。对于这个策略,在 LevelDB 实现文档 中的描述为:
Compactions for a particular level rotate through the key space. In more detail, for each level L, we remember the ending key of the last compaction at level L. The next compaction for level L will pick the first file that starts after this key (wrapping around to the beginning of the key space if there is no such file).
相关源码为:
1 | // db/version_set.cc |
其他细节:
- 上面代码中的
c->inputs_是两个的FieldMetaData*数组,代表 level 与 level+1 的 compaction inputs。 - 如果要 compaction 的 level-0,则会继续把 level-0 中与
c-inputs_[0]中有 overlap 的所有文件也加入c->inputs中。还有一个注意的点,在计算 overlapping 的文件时,会逐步扩增 key 的范围直至最大,每一次扩增会重零开始收集 overlapping 的文件。
注意到最后还调用了一个 VersionSet::SetupOtherInputs 方法来获取所有 compaction 所需要的 inputs。这里面也是细节满满,主要目的是尽可能多地选择更多文件进行 compaction:
- 如果 inputs 中的一个文件的上界等于该 level 中的某一个文件的下界,需要把该文件也加入 inputs 中。这里可能会有个疑惑,就是按理来说同一层(除了 level-0)的 SST 应该不会出现这种情况,其实这种情况是可能出现的,因为 LevelDB 支持了快照(Snapshot)的功能,所以在有快照存在的情况下,同一层的 SST 之间是可能存在重复的 key 的(user_key 相同,seq不同)。这种情况下,这两个文件如果不一起合并,则可能会导致后续的
Get操作读到旧数据。 - 初步拿到两层的 inputs 之后,会通过现在总的上界和下界去继续扩大 level 的文件范围,然后再继续扩大 level+1 文件的范围,由此反复,直到无法继续进行或总的要 compaction 的文件大小(level 和 level+1)达到上限:25 倍的
max_file_size(默认是 2MB)。 - 最后会将 level 的孙子(level+2)与最终的 inputs 有 overlapping 的文件记录下来供之后使用。
接下来就是正式的进行 compaction 了。由 DBImpl::DoCompactionWork 这个方法完成。先来看下 impl 文档的描述:
A compaction merges the contents of the picked files to produce a sequence of level-(L+1) files. We switch to producing a new level-(L+1) file after the current output file has reached the target file size (2MB). We also switch to a new output file when the key range of the current output file has grown enough to overlap more than ten level-(L+2) files. This last rule ensures that a later compaction of a level-(L+1) file will not pick up too much data from level-(L+2). The old files are discarded and the new files are added to the serving state.
一般情况下很好理解,结合源码来看,首先会为 compaction inputs 生成一个 MergingIterator,这个迭代器的作用就i是每次返回一个最小最新的 key(这里还涉及 key 以及 user_key 的关系与编码,以及 comparator 的实现,之后再看)。在一般情况下,会构建一个新的 output 文件,将每次迭代的结构 add 到该文件中,如果这个 output 文件达到了 max_file_size(默认 2MB),便会将这个文件落盘,然后创建一个新的 output 文件,后续的 kv 继续添加到新文件中。在添加到新文件之前,需要判断是否该 key 是否已经加入了(最新的 key 会先加入)或者是否是 Delete 操作,这种 key 直接抛弃(不加入到 output 中)。
这里依然存在一些特殊情况与细节:
- 如果在归并过程中发现有新的 immutable
MemTable生成,需要先将其 dump 到 level-0。 - 如果在归并过程中发现与 level+2 层的 overlapping 过大,不用等到
max_file_size就直接生成 output 文件,之后的 key 进入新 output 文件。 - 如果 level+2 层及更高层的 level 包含了某 key,那么此层的 compaction 不能直接丢弃掉
Delete操作的 key。
做完 merge 之后会调用 DBImpl::InstallCompactionResults 标记需要删除的文件与新加入的文件,并进一步调用 VersionSet::LogAndApply 更新 DB 的元信息并重新评估各 level 的 score。最后再调用 DBImpl::CleanupCompaction 清理 compaction 过程占用的内存与 pending_outputs_ 解除对文件的锁定,最后在调用 DBImpl::RemoveObsoleteFiles 清理到上面说的标记为删除的文件,这样就完成了一次 compaction。
如何评估一个 level 是否该被 compaction
最后快速看一下 VersionSet::Finalize 这个方法,这个方法会在 VersionSet::LogAndApply 和 VersionSet::Recover 中被调用,是在某个操作收尾时重新对所有 level 进行评估,来得出下一次 compaction 的 level。这个评估的策略非常简单,就是给每一层打分,每一层的分数就是该层的文件总大小除以该层的最大容量阈值(L层的阈值为 10^L MB),下一次 compaction 会选择分数最大的层。level-0 比较特殊,它的分数为文件数除以 config::kL0_CompactionTrigger(也就是 4)。
总结
总结来说,一次 compaction 操作一般只会选择一个 level 的一个文件及其 overlap 的文件(除非 compaction 过程中生成了 immutable MemTable,这种情况会立即进行一次 minor compaction)。再一次 compaction 之后会立刻对所有 level 进行重新评估,然后再次调用 DBImpl::MaybeScheduleCompaction 查看是否还能继续 compaction,如果可以,则往后台任务队列提交一个新的 compaction 任务。这样看下来,LevelDB 的写放大问题还挺大的。
最后用伪代码简单梳理一下整个 compaction 的逻辑:
1 | // db/db_impl.cc |
数据压缩的粒度是什么
Block。进行 WriteBlock 时会调用 port::Snappy_Compress;进行 ReadBlock 时会调用 port::Snappy_Uncompress。
如何保证 snapshot 不被 compaction 掉
在调用 DBImpl::DoCompactionWork 中会为 CompactionState 实例 compact 设置一个 smallest_snapshot 字段,如果 DBImpl 实例中有 snaphost,则将其设置为最老的那个 snaphost 的 seq,否则设置为最新的 seq。这个 smallest_snapshot 字段会在后续用于判断是否要删除这个 key,剩下的完整的逻辑就不言而喻了。
key 是如何组织和进行比较的
在 MemTable 中,一条 kv 记录(entry)的格式是这样的:
1 | Format of an entry is concatenation of: |
由此可见,一个 entry 里还带有 seq,在比较(或者说做排序)的时候会同时依照 key (aka. user_key) 和 seq (其实还有 type,但是 user_key 和 seq 其实已经足够了)来判断。具体的策略是,按照 user_key 升序排列,同样的 user_key 按照 seq 降序排列(同样的 user_key 依照 type 降序排列,应该不会用到这个策略)。
在 SST 中,顺序是和 MemTable 中的顺序是一致的。
所以不管是在 MemTable 还是在 SST 中,都是相同的 user_key user_key 更小,seq 更大的在前面。举个例子,如果用 key_seq 来表示一个 entry,那么可能会存在这样的一个序列:k1_10, k1_7, k1_3, k2_11, k3_9….